
The whole Arvados team is thrilled to announce the release of Arvados 3.0.0. This is a major release with many significant improvements that we’ve been working on throughout this year while delivering smaller, less disruptive changes in Arvados 2.7 series of releases. With so much cool new stuff, we wanted to take this opportunity to highlight changes that most users will see and benefit from immediately.
New Workbench Project View
The project view has been completely revamped to streamline your work and use the space to show you more information more relevant to you. The project name appears at the top of the page, followed by an action toolbar with all the operations you might want to perform. If you’re looking for more information about this project, you can pull down the chevron to see the full project description (which can include HTML) and metadata properties.
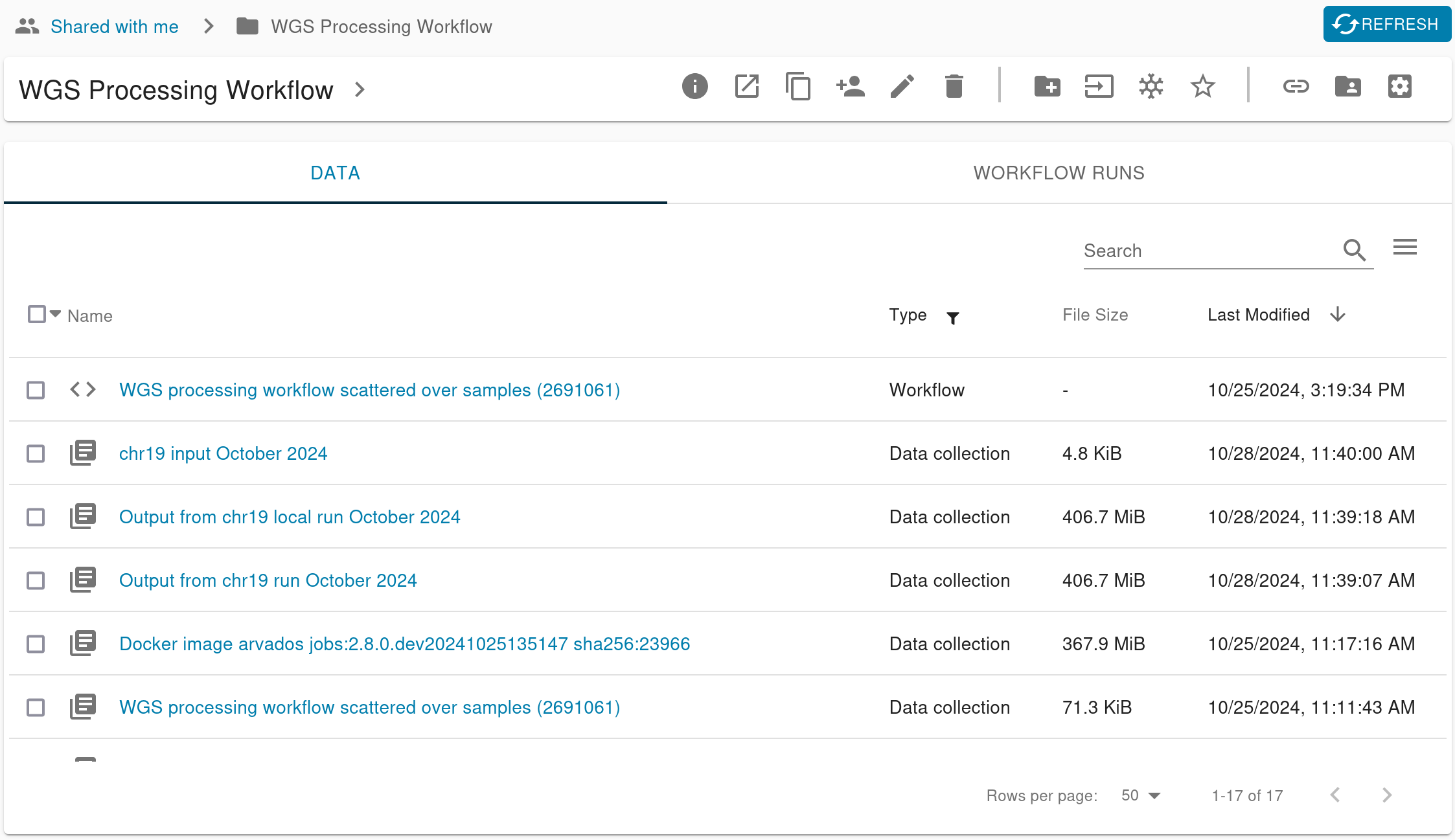
Below that, the contents listing is now split into two tabs: Data and Workflow Runs. The Data tab lists the project’s collections and workflow definitions. The Workflow Runs tab lists all the workflow runs under this project. Based on feedback from users, we think this will make it easier for people to focus on their common tasks: launching workflows, checking progress, and reviewing results. Whatever you’re looking for, you should be able to find it faster now that workflow runs and their outputs aren’t weaved together chronologically. It also means the listing columns are more relevant and focused: the Data tab shows information relevant to inputs and results, while the Workflow Runs tab shows another set relevant to ongoing work.
You can still sort and filter the listings just like before, so you can still limit the Data tab to showing only output collections, on the Workflow Runs tab to show processes with the oldest first. None of that functionality is going away. Instead you can think of the tabs as a sort of “pre-filter” on the listing.
Launch Workflows With Ease
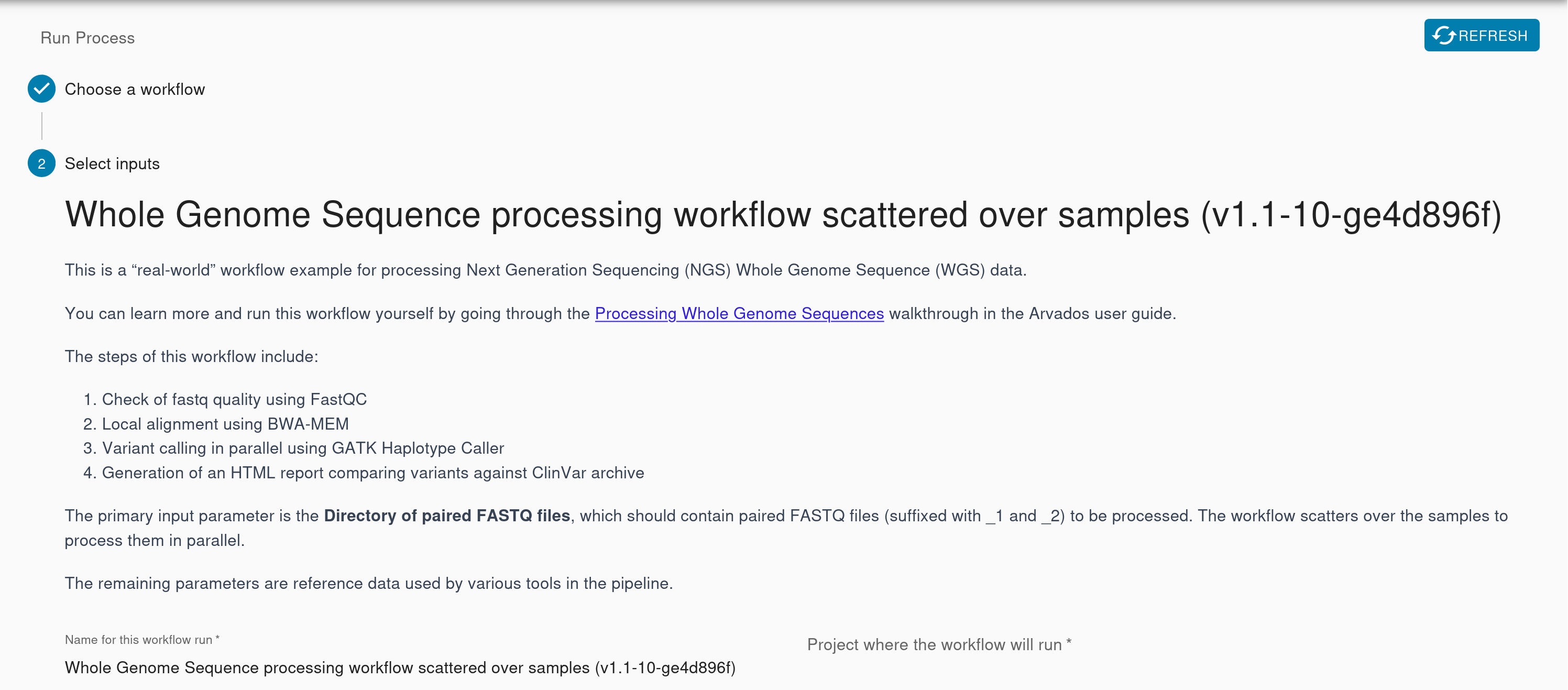
We’ve made improvements to all the different interfaces you use to run a workflow so you have the information you need at your fingertips without cross-referencing resources. After you select your workflow, the dialog shows the full workflow description, which can include instructions about how to select inputs or set parameters.
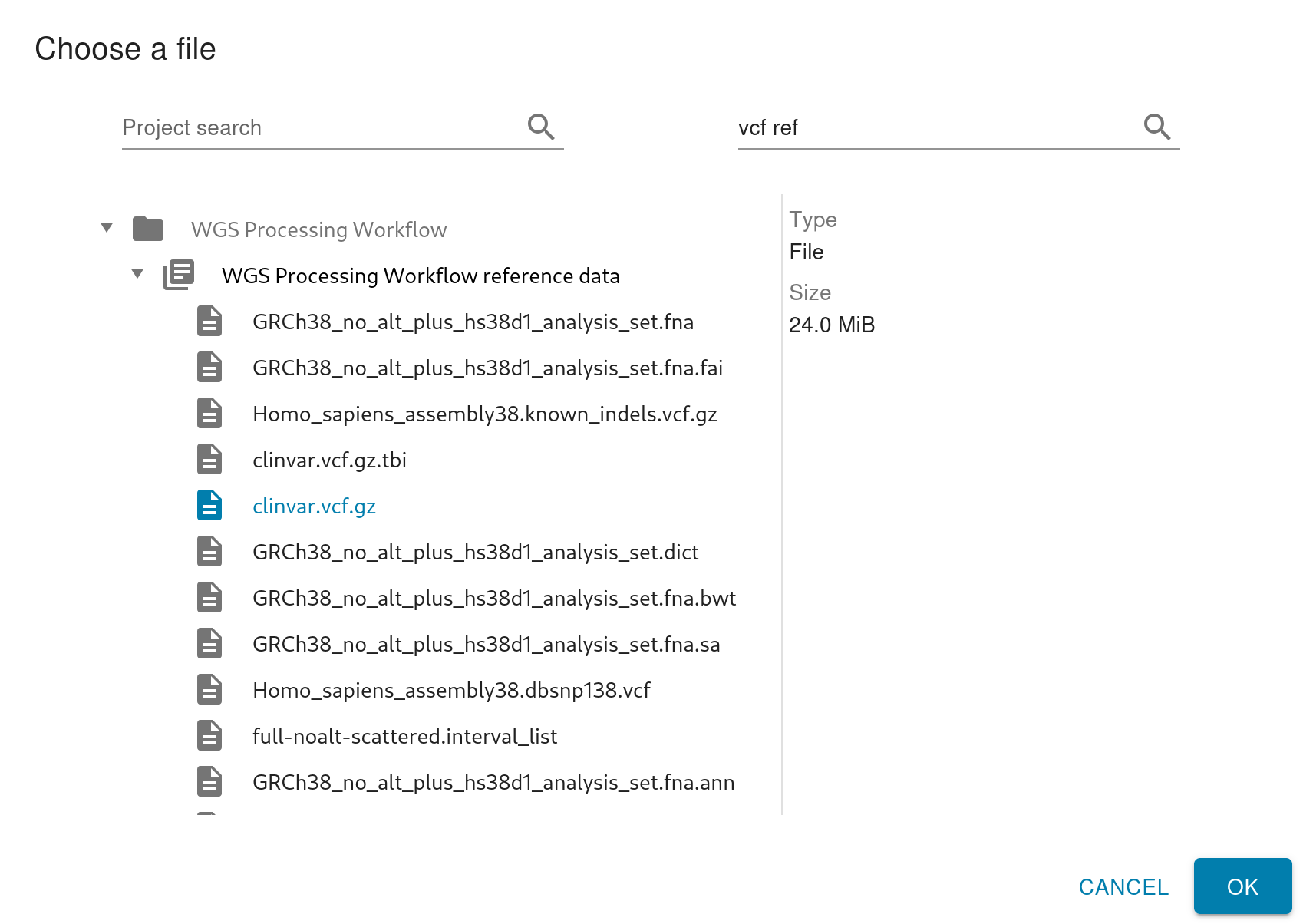
The input selection dialog always shows the parent project containing your selection. If you search for a project, you won’t get a flat listing of results anymore. Instead, the results will show you what projects those collections live in. To help with that even further, you can select any item to see more information about it in the right pane, even if it’s not the type of object you need to select for this input. This makes it easier to find and select the item you need from this dialog.
Workflow secret inputs are now fully supported. You can register workflows with secret inputs, launch them from Workbench, and have that data handled securely throughout.
Once you’ve started your workflow, if you’re using Arvados’ cloud dispatcher, the Logs pane will now give you updates about where your process is in the queue or the bootstrapping process. This gives users more information about what kind of turnaround time to expect. Future versions of Arvados may provide this information for other Crunch dispatchers.
Once your workflow is completed, you can go to the Resources pane of any step to get a report with more information about how that process used its hardware resources like CPU, memory, and network. If you’ve used the crunchstat-summary report before, this is the same report, but now it’s automatically generated when the workflow is run, and made available directly through Workbench. This makes it easier for users to diagnose resource problems in their workflow definitions and make appropriate adjustments.
Performance Improvements
Under the hood, we’ve refined Workbench’s network requests to make them more efficient, so it gets the data it needs with fewer round trips. This makes searching and browsing in Workbench more responsive throughout whether you’re browsing projects, launching a workflow, or reviewing results.
Some of those speed improvements happened directly in the API server. Text searches now ignore identifier columns like UUIDs and portable data hashes, so they return more relevant results faster. API listings can now include more referenced resources. Clients like Workbench can request all the information they need in a single request.
Data management is faster thanks to various performance improvements across Keep services. The core Keepstore service has a new streaming architecture that can start sending a data block to clients before it’s fully read, reducing time to first byte and other key performance metrics. Keep still preserves integrity by terminating the connection early if the data block does not match its checksum, so clients still have that guarantee without implementing their own checks.
Consumers like keepproxy and keep-web now cache more data to make fewer network requests. They also make better use of the replace_files parameter to update collections to reduce the amount of data that needs to be transferred for common changes to data sets.
Better Documentation
The reference documentation for the Python and R SDKs is now much more complete with full descriptions for every API method, parameter, and result. This documentation is generated from information in the Arvados API “discovery document,” so we can incorporate it into other SDKs’ documentation in the future.
The documentation is also streamlined because we have removed obsolete APIs from both Arvados itself and the Python SDK in Arvados 3.0. We’ve also reorganized the Python SDK so private support code is clearly marked and not covered in the reference documentation. Thanks to all this, the documentation is much more focused on the interfaces you should use, with less cruft in the way.
That’s Not All
Arvados 3.0 has been in the works through much of the year and we’re really excited for you all to start using it. Because this is such a big release, administrators should make sure to check out the upgrade notes for important information about how to upgrade their clusters. Anyone looking for even more detail about what’s new can check out our full release notes.
If you’re not using Arvados yet, the new version is already running on our Arvados Playground, where anyone can make an account and try it out. If you’d like help installing or upgrading your own cluster, Curii has consulting and support services that can help. Get in touch with us at info@curii.com.